Splunk Docs
help.splunk.com
검색어 작성 기법

1 : 목록에서 설치된 앱 선택
기본앱 : Search&Reporting
- 엄밀히 말하면 splunk를 사용하는게 아니라 search &reporting 앱을 쓰는 것
2 : 사용자가 검색어를 입력하는 창
3 : 검색 명령어를 적용할 시간 범위
4 : 검색 실행
5 : 과거 검색한 이력
작업의 '검색에 추가' 를 입력하면 2 검색창에 복사
1. 기본 검색
1-1. 기본 검색
error - error가 포함된 모든 로그를 반환
error* - error로 시작하는 errorpage,error_id 등을 찾을 수 있음
두 단어 이상의 검색은 띄어쓰기로 구분
대소문자 구분 안함 : erro , ERROR, Error 다 똑같음
1-2. boolean 연산자
* AND, OR, NOT 반드시 대문자로 입력
* 괄호 : 우선 순위 지정
error* web-server (denied AND (401 OR 403))
괄호 중첩시 가장 안쪽 괄호부터 해석
-> 401과 403 중에 하나의 값이 denied와 동시에 나타나는 로그를 검색한다. 이후 error*로 시작하는 단어와 web-server가 포함되 결과를 반환한다.
1-3. 따옴표(")
따옴표로 감싸면 하나의 단어로 인식
access denied는 access와 denied 두 단어로 반환
"access denied"는 하나의 단어로 그대로 검색
1-4. 시간
1-4-1 절대시간
earliest=<시간 연산자> latest=<시간 연산자>
%m/%d/%Y:%H:%M:%S
2024년 8월 21일 오후 1시 ~ 2024년 9월 1일 오후 1시
earliest=8/21/2024:13:00:00 lastest=9/1/2024:13:00:00
1-4-2 상대시간
* 빼기(-) 또는 더하기(+)로 사용
* 1이 포함된 것으로 간주 -> s => 1s m=>1m
* 시간차이 검색
- @ 문자는 반내림
-[+|-]<시간_정수><시간단위>@<시간단위>
예) 2시간 이전부터 로그 검색
earliest=-2h@ latest=now
예) 현재시간이 오후 4시반 -2h : 2시간 이전인 오후 2시반 하지만 - 2h@이니까 2시반이 아니라 가장 가까운 시간으로 반내림해서 오후 2시가 검색 시작시간이 된다
예) 이전달의 모든 이벤트 검색
earliest=mon@mon laste=@mon
예) 이전주, 직전일 이벤트
earliest=w@w latest=@w
earliest=d@d latest=@d
| 시간 범위 | 사용 키워드 |
| 초 | s,sec,secs,second,seconds |
| 분 | m,min,minute,minutes |
| 시간 | h,hr,hrs,hour,hours |
| 일 | d,day,days |
| 주 | w,week,weeks |
| 개월 | mon,month,months |
| 분기 | q,qtr,qtrs,quarter,quarters |
| 년 | y,yr,yrs,year,years |
2. 검색에서 필드 활용
domin=google.com
도메인 필드에 google.com이라는 문자열이 있는 검색 결과를 보여준다
index=book sourcetype=dns domain=google.com
모든 검색어는 공백으로 구분
index=book sourcetype=dn domin=*.google.com
* 있고 없고의 차이는
업으면 : 정확히 google.com만 찾음
있으면 : *.google.com -> www.google.com, mail.google.com 등 검색 결과로 보여줌
주의사항 : 필드값은 대소문자를 구별하지 않지만, 필드명은 대소문자를 구별
http_status와 HTTP_status는 전혀 다른 필드이다
필드에 IP가 있다면 CIDR 형식 가능
src="192.168.10.*"
src="192.168.10.0/24"
숫자 값이면 비교 연산자 가능
src_port > 5000 AND src_port <6000
3. 검색 처리 언어 및 파이프
파이프
index=book sourcetype=access_combined status=404 | stats count by url
- index=book sourcetype=access_combined 로그에서 상태코드가 404인 로그를 추출
- url 기준 개수를 반환
=> 최종 결과, status가 404인 uri 종류별 개수를 결과로 보여줌
index=book sourcetype=access_combined status=404 | stats sum(cost) as total by prodcutID | where total > 100ctrl+\ 하면 정렬해줌 아니면 애초에 설정
index=book sourcetype=access_comned status=404
| stats sum(cost) as total by prodcutID
| where total > 100
4. 검색 명령어
1. 데이터 나열, 변환
table
table <<필드 1>> <<필드2>><<필드3>>...<<필드 n>>
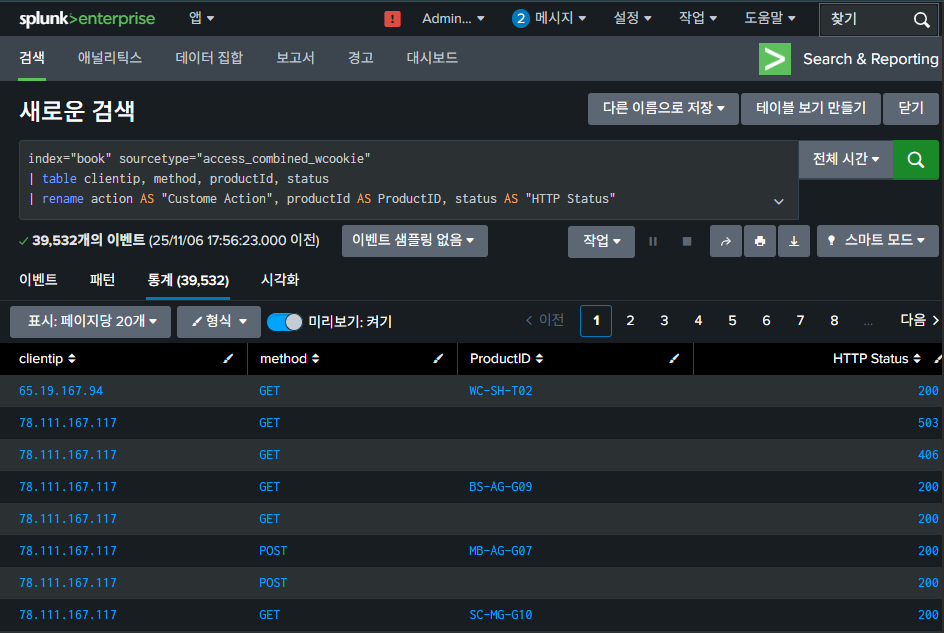
index="book" sourcetype="access_combined_wcookie"
| table clientip, method, productId, status
rename
다른 필드명으로 변경
rename <<원래필드명>> AS <<변경하려는 필드명>>
fields
특정 필드를 포함시키거나 제거할때 +혹은 - 로함
dedup
검색 결과에서 중복제거
dedup <필드명1> , <필드명2> ..
sort
기본값은 오름차순, 내림차순 정렬시 마이너스(-)를 붙임 2개이상 필드를 동시에 정렬도 가능함
sort (+|-) <필드1>...
index=book sourcetype="access_combined_wcookie"
| table clientip, action, productId
| sort action, -productId예를 들어 IP 주소로 정렬을 원하면
| sort -ip(IP필드)
2. 통계 계산
stats
...|stats [count|dc|sum|avg|list|values] by[필드명]
| 함수명 | 설명 |
| count(x) | x 필드의 개수를 반환 |
| dc(x) | x 필드의 중복을 제한 개수를 반환 |
| sum(x) | x 필드의 총합을 반환 |
| avg(x) | x 필드의 평균을 반환 |
| list(x) | x 필드의 목록을 반환 |
| values(x) | x 필드의 중복을 제거한 목록을 반환 |
| max(x) | x 필드의 최댓값을 반환 |
| median(x) | x 필드의 중앙값을 반환 |
| min(x) | x 필드의 최솟값을 반환 |
| var(x) | x 필드의 분산값을 반환 |
| stdev(x) | x 필드의 표준편차를 반 |
index=book sourcetype="access_combined_wcookie"
| stats sum(bytes), avg(bytes), max(bytes), median(bytes),min(bytes) by clientip
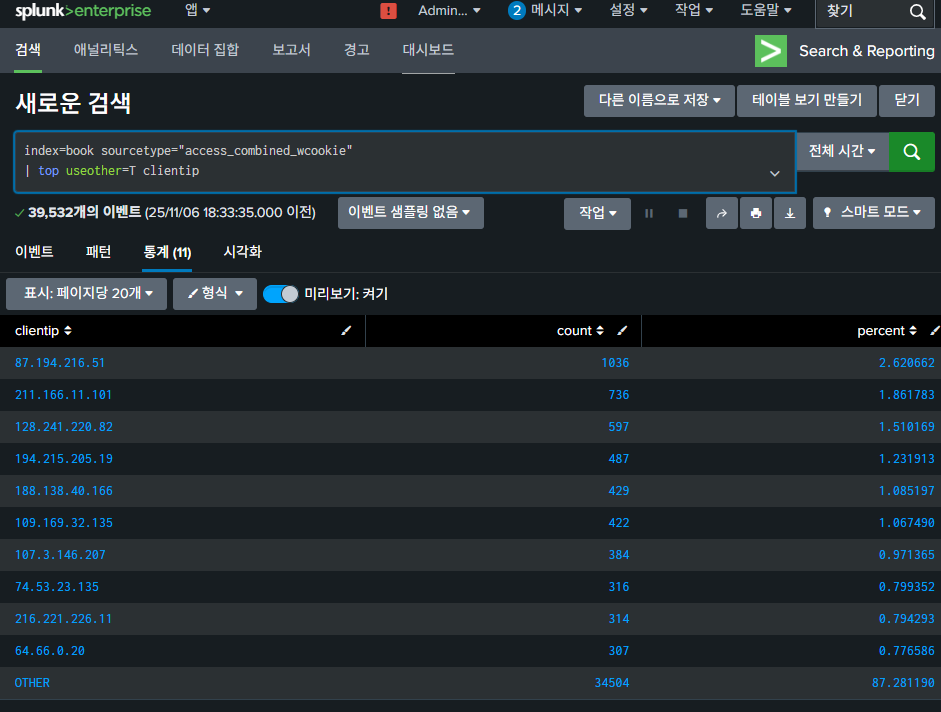
top * 제일 많이씀
지정필드에서 가장 많이 나오는 값
<검색어> | top limit=<숫자> [showperc=T/F] [showcount=T/F] [useother=T/F] 필드1, 필드2 by 필
limit 지정하지 않으면, limit=10이 자동으로 설정됨
showperc 는 해당 값이 차지하는 비율
showcount는 해당 값의 개수
-> 기본 값이 T
다른 숫자의 크기를 알아보려면 useother=T -> 전체의 수와 비율을 알 수 있다.
index=book sourcetype="access_combined_wcookie"
| top clientip by method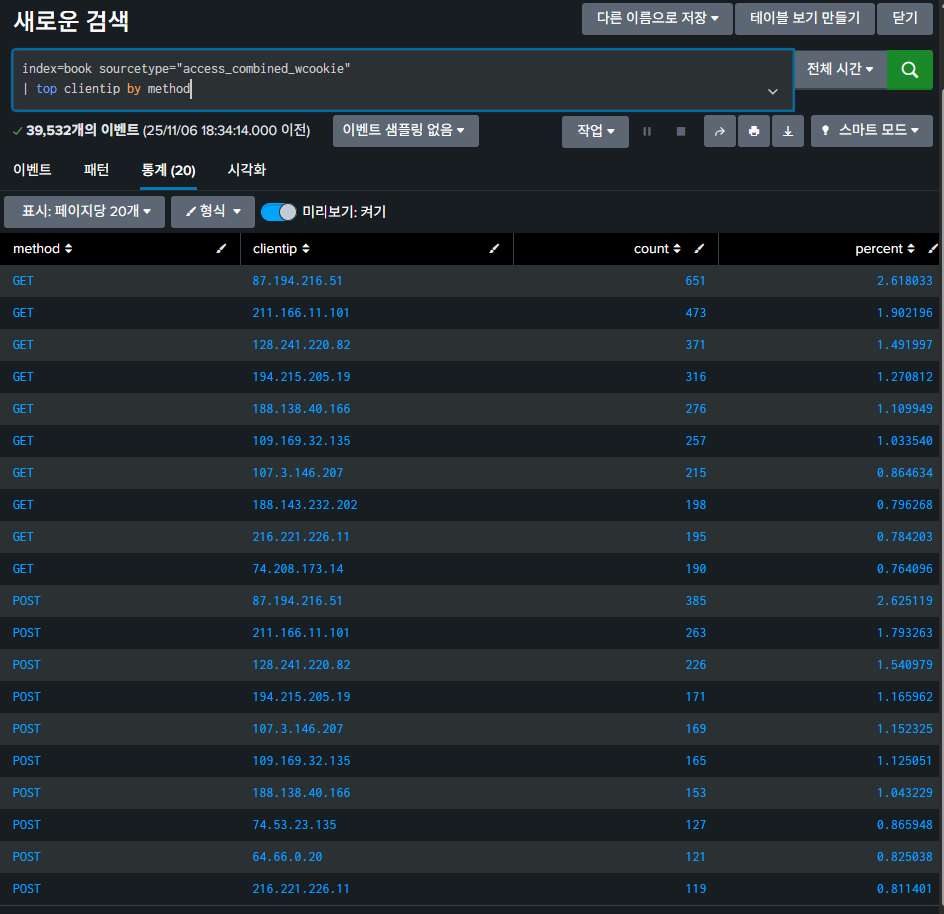
rare
- top과는 정반대로 결과인 빈도가 적은 값의 순서를 추출 top 으로 추출한 결과를 역으로 정렬하면 rare의 결과가 나온다.
<검색어> | rare [limit=숫자] [showperc=T/F] [showcount=T/F] [useother=T/F] 필드1, 필드2 by 필드
예) 사용자 컴퓨터에 설치된 프로그램 목록을 추출 -> 모든 컴퓨터에 설치되어있으면 서치한 컴퓨터 숫자도 많이 나타남. 하지만, 소수의 컴퓨터에서 동작 중인 프로그램이 있으면 작은 숫자로 나타남 => 허가받지 않은 프로그램이거나 사용자 몰래 설치된 프로그램일 수 도 있다.
len(x)
문자열의 길이를 양의 정수 값으로 돌려준다.
예를 들어 도메인 길이가 비정상적으로 길다면 정상 도메인이 아님
3. 차트시각화
tiemchart
- 시간에 따른 통계 테이블이 생성
- 시간에 따른 통계의 추세를 표시할 때 가장 많이 사용됨
timechart span=[시간범위] 통계함수 by [필드명]
index=book sourcetype="access_combined_wcookie"
| timechart span=12h count(clientup) as "Access Count"
chart
- 임의의 필드를 x축으로 사용할 수 있음
- chart [통계함수] over x축 by [기준필드]
-예) 웹로그에서 날짜별 고유 접속 IP 수를 얻는 검색어
index=book sourcetype="access_combined_wcookie"
| chart dc(clientip) as "Unique Count" over date_wday
4. 비교분석
eval
- 검색 결과 값의 변환, 검증을 수행하며 함수 실행 결과 값을 변환
- ...|eval [반환값_저장변수] = 함수(인자1, 인자2..)
- 문자열을 인자로 취하고 결과값을 반환함 ""로 감싸서 표시
case(X,"Y",...)
- 여러개 조건을 검증할 때 사용
...
| eval description=case(error == 404, "Not found", error == 500, "Internal Server Error", error==200,"OK")
case함수를 이용해서 월 이름을 기반으로 분기(quarter)를 반환하는 코드를 작
...
| eval quarter=case(date_month="january", "1Q", date_mont"february", "1Q",date_month="march", "1Q",date_month="april","2Q",...)cidrmatch("X",Y)
- IP 주소 Y가 네트워크 범위 X에 존재하는지 확인
...
| eval local = cidrmatch("10.0.0.0/8","10.10.0.100")...| where (cidrmatch("10.0.0.0/8",ip) OR
cidrmatch("172.16.0.0/12",ip) OR
cidrmatch("192.168.0.0/16",ip))if(X,Y,Z)
-x가 참이면, y를 실행하고 x가 거짓이면 z를 실행한다.
*| eval ip1="10.10.0.100", ip2="100.10.0.100"
| eval network1=if(cidrmatch("10.10.0.0/24",ip1),"local","external"),network2=if(cidrmatch("10.10.0.0/24",ip2),"local","external")
| table ip1, network1, ip2, network2
like(X,"Y")
- x필드에서 일부문자열인 y를 찾는다
- %를 와일드카드로 쓰는건 like()함수만임
like(domian,%.ac%) : domain에서 .ac.를 찾아서 존재하면 참을 반환
...| where like(field,"addr%") : field 변수가 addr로 시작하는지를 검사한다.
match(X,"Y")
- 정확한 일치 여부를 비교
- 대소문자 구분하지 않
match(filename,"malicious.exe") : filename이 malicious.exe와 정확히 같으면 참
match(filename,"(.jpg|.gif|.png)$") : filename이 .jpg, .gif, .png로 종결($)하는 지 검사
5. 다중 문자열과 시간
mvindex(X,Y,Z)
- 필드 x에 있는 y번째 값을 반환
- y는 인덱스 번호이며, 0이 첫번째 값을 의미함/ 뒤에서 부터 세고 싶으면 -1 / -2는 마지막에서 두번째 값
- z는 선택적 사용 / z값 지정 시 y부터 z까지 값을 반환
split(X,"Y")
- y를 이용해서 x를 분할해 다중 값 형식으로 반환
substr(X,Y,Z)
- z가 없으면 필드 x의 y(1부터 시작)부터 끝까지 반환
- z가 있으면 y부터 z까지 반환
*| eval passwd_str="lightdm:x:107:117:Light Display Manager:/var/lib/lightdm:/bin/false"
| eval uid=mvindex(split(passwd_str,":"),0)
| eval subuid1=substr(uid,2)
| eval subuid2=substr(uid,2,4)
| table uid, subuid1, subuid2
round(X,Y)
- x를 y자리수 기준 반올림한다
- round(2.555,2) : 2.56
urldecode(X)
- URL인코딩이 되어있는 x를 디코딩해 반환한다.
- 한글도 가능

strftime(X,Y)
- 유닉스 시간 x를 지정한 y 형식으로 출력
strptime(X,Y)
- y형식으로 된 x시간 문자열을 입력받아서 유닉스 시간으로 반환
index=book sourcetype="access_combined_wcookie"
| eval unixtime = strptime(req_time,"%d/%B/%Y:%H:%M:%S")
| eval humantime = strftime(unixtime,"%Y-%m-%d %H:%M:%S")
| table req_time,unixtime, humantime
now()
- 실행시킨 시간을 유닉스 시간 형식으로 반환
- 탐지 시스템이 공격을 탐지한 후 오늘까지 얼마나 시간이 흘렀는지를 계산할 때 기준점으로 사용함
index=book sourcetype="access_combined_wcookie"
| eval unixtime = strptime(req_time,"%d/%B/%Y:%H:%M:%S")
| eval date_diff=round((now()-unixtime)/86400,0)
| table req_time,date_diff| eval date_diff=round((now()-unixtime)/86400,0)
- 하루가 86400

4. 검색어 작성
index=book
| eval uri="/tools/refresh.html?category=computer&company=first&cpu=i7"
| eval uri1="/edgedl/toolbar/t7/data/7.5.8231.2252/GooglebarInstaller_updater_signed.exe"
| eval filename=if(like(uri,"%?%"),mvindex(split(mvindex(split(uri,"?"),0),"/"),-1),mvindex(split(uri,"/"),-1))
| eval filename1=if(like(uri1,"%?%"),mvindex(split(mvindex(split(uri,"?"),0),"/"),-1),mvindex(split(uri1,"/"),-1))
| table filename, filename1
5. 검색 효율성 높이기
5.1 시간 범위 지정하기
5.2 인덱스 이름 지정하기
5.3 최대한 자세한 검색어 사용하기
5.4 검색 필터는 검색어 처음에 사용하기
5.5 와일드 카드 사용 자제하기
5.6 fileds 명령어 적극 사용 하기